AI
Ollama
What is ollama?
Ollama is a free, open-source tool that allows users to run large language models (LLMs) on their own computers. LLMs are AI programs that can understand and generate human-like text, code, and perform other analytical tasks.
Install
Linux
$ sudo apt install pciutils lshw
$ curl -fsSL https://ollama.com/install.sh | sh
macOS
Download it here
Windows
Download it here
Linux Manual Install
$ curl -L https://ollama.com/download/ollama-linux-amd64.tgz \
-o ollama-linux-amd64.tgz
Extracts the contents of the ollama-linux-amd64.tgz and places the extracted files into /usr:
$ sudo tar -C /usr -xzf ollama-linux-amd64.tgz
Run Ollama for tests:
$ ollama serve
Open another terminal and verify that Ollama is running:
$ ollama -v
Make Ollama as a startup service?
The latest version of Ollama will set up user and service for you during installation.
Install CUDA
Checkout the instructions here
Customizing
$ sudo systemctl edit ollama
Alternatively, create an override file manually in /etc/systemd/system/ollama.service.d/override.conf:
[Service]
Environment="OLLAMA_DEBUG=1"
Updating
Update Ollama by running the install script again:
$ curl -fsSL https://ollama.com/install.sh | sh
Or by re-downloading Ollama:
$ curl -L https://ollama.com/download/ollama-linux-amd64.tgz \
-o ollama-linux-amd64.tgz
$ sudo tar -C /usr -xzf ollama-linux-amd64.tgz
View Logs
Linux
$ sudo journalctl -u ollama --follow
macOS
$ tail -f ~/.ollama/logs/server.log
Windows
$ type "$env:LOCALAPPDATA\Ollama\logs\server.log"
Docker
$ docker ps # find container ID/name
$ docker logs <container-name> --follow
Uninstall Manual Installation
Remove system service:
$ sudo systemctl stop ollama
$ sudo systemctl disable ollama
$ sudo rm /etc/systemd/system/ollama.service
Remove the ollama binary from your bin directory (either /usr/local/bin, /usr/bin, or /bin):
$ sudo rm $(which ollama)
Remove the downloaded models and Ollama service user and group:
$ sudo rm -r /usr/share/ollama
$ sudo userdel ollama
$ sudo groupdel ollama
Ollama Commands
List models:
$ ollama list
Remove a model:
$ ollama rm <model name>
List which models are currently loaded
$ ollama ps
Stop a model which is currently running
$ ollama stop llama3.2
Expose Ollama
macOS
- Stop the Ollama application: Ensure the Ollama app is not running.
- Set the environment variable: Open Terminal and run:
$ launchctl setenv OLLAMA_HOST 0.0.0.0:11434
- Restart Ollama: Relaunch the Ollama application from your Applications folder. It will now listen on all network interfaces.
Linux
- Edit systemd service by calling
sudo nano /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_DEBUG=1"
- Reload systemd by calling following commands:
$ sudo systemctl daemon-reload
$ sudo systemctl restart ollama
Windows
On Windows, Ollama inherits your user and system environment variables.
- First Quit Ollama by clicking on it in the task bar.
- Start the Settings (Windows 11) or Control Panel (Windows 10) application and search for environment variables.
- Click on Edit environment variables for your account.
- Edit or create a new variable for your user account for
OLLAMA_HOST,OLLAMA_MODELS, etc. - Click OK/Apply to save.
- Start the Ollama application from the Windows Start menu.
Nginx
server {
listen 80;
server_name example.com; # Replace with your domain or IP
location / {
proxy_pass http://localhost:11434;
proxy_set_header Host localhost:11434;
}
}
Ngrok
Ollama can be accessed using a range of tools for tunneling tools. Run the following command for test purposes:
$ ngrok http 11434 --host-header="localhost:11434"
Alternatively, edit the Ngrok config file manually in ~/.config/ngrok/ngrok.yml or run the following command:
$ ngrok config edit
Grab your Ngrok token and free domain name and replace them in the config file:
version: 3
agent:
authtoken: 2n*******************
tunnels:
ollama:
proto: http
addr: 11434
domain: example.ngrok.app
request_header:
add: ["Host: localhost:11434"]
Start your tunnel:
$ ngrok start ollama
# or
$ ngrok start --all
Run Ollama
$ ollama run llama3.2:3b
#or
$ ollama run mistral
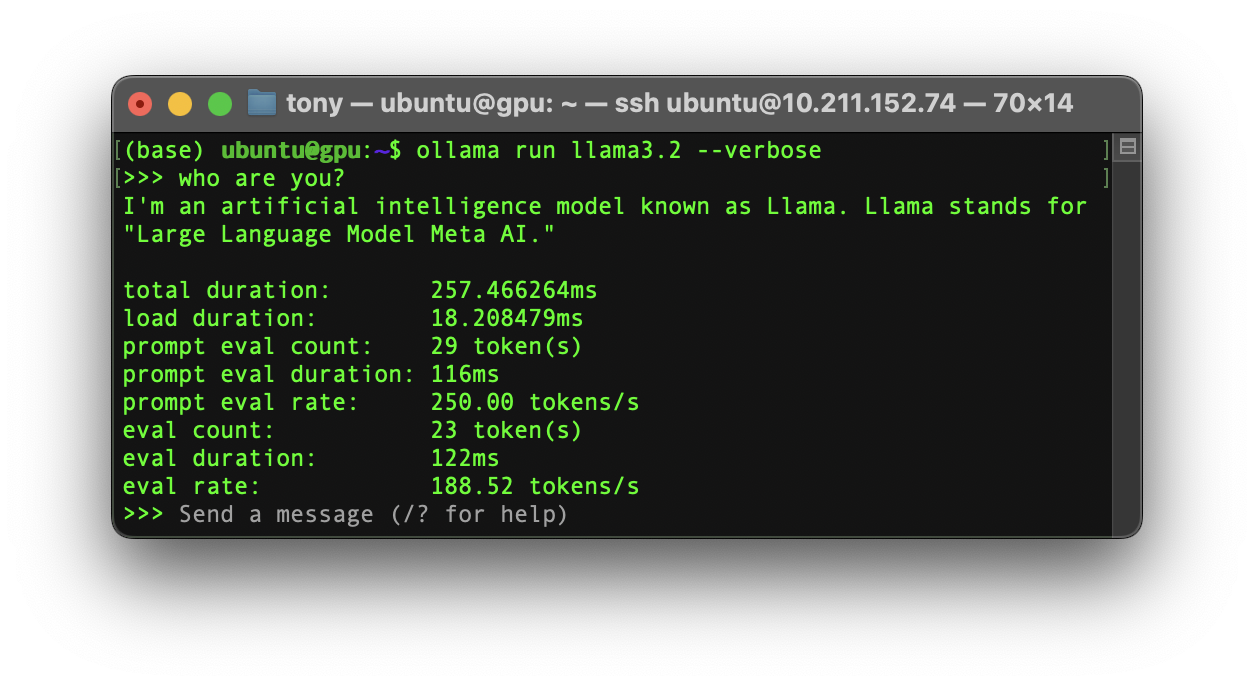
If you want to monitor a Ollama geneartion performance:
$ ollama run llama3.2 --verbose
API
Generate Embeddings
$ curl http://localhost:11434/api/embed -d '{
"model": "nomic-embed-text",
"input": "Why is the sky blue?"
}'
Multiple Text Inputs:
curl http://localhost:11434/api/embed -d '{
"model": "all-minilm",
"input": ["Why is the sky blue?", "Why is the grass green?"]
}'
Tags
curl http://localhost:11434/api/tags
How to troubleshoot issues
$ cat ~/.ollama/logs/server.log
#or
$ journalctl -u ollama --no-pager --follow --pager-end
FAQ
How can I tell if my model was loaded onto the GPU?
Use the ollama ps command to see what models are currently loaded into memory.
| NAME | ID | SIZE | PROCESSOR | UNTIL |
|---|---|---|---|---|
| llama3:70b | bcfb190ca3a7 | 42 GB | 100% GPU | 4 minutes from now |
How do I manage the maximum number of requests the Ollama server can queue?
If too many requests are sent to the server, it will respond with a 503 error indicating the server is overloaded. You can adjust how many requests may be queue by setting OLLAMA_MAX_QUEUE.
Where are models stored?
- macOS:
~/.ollama/models - Linux:
/usr/share/ollama/.ollama/models - Windows:
C:\Users\%username%\.ollama\models